LLM Explained: The LLM Training Landscape
Originally published on Medium on August 6, 2023. https://medium.com/@liu-gendary/llm-explained-the-llm-training-landscape-82c803495caa

Since the introduction of Transformer model in 2017, large language models (LLMs) have evolved significantly. ChatGPT saw 1.6B visits in May 2023. Meta also released three versions of LLaMA-2 (7B, 13B, 70B) free for commercial use in July.
In this post, I will explain how a LLM like ChatGPT or LLaMA came to life, from pre-train, to fine-tune and reinforcement learning from human feedback (the “make AI” process). I will also talk about some common approaches of model observability, guardrail, and governance. In the next series, I will explain the “use AI” — inference process.
Pre-training:
The training process starts with building a pre-training model. The goal here is to teach the base model to generate more text data and complete documents by reasonably predicting the next words. In order to do this, researchers and developers expose the transformer model to a large amount of training dataset, usually texts with trillions of words, yet low-quality, unsupervised, and unstructured. The texts are then tokenized into a long list of integers. The transfer model will find optimal patterns and likelihoods between the text words, and the patterns will be stored as “weights” — consider them as the coefficients of a polynomial. The more parameters the models has, the more flexibility the model has to capture details and relationships of the trained text.
Think of training as of a continuous refining process. Through thousands of iterations, making not so good predictions, and receiving feedback, the transformer model learns to make less bad predictions and gradually gets closer to the correct predictions — updating and optimizing weights.
Models like GPT, LLaMa, and PaLM are all pre-trained base models in general language domains. While BioGPT, BioBERT, and PubMedBERT are domain-specific pre-trained models, which were exposed to biomedical texts during pre-training.
Challenges and Requirements:
The pre-training process is capital-, compute-, time-, and memory-intensive.
So, how does compute hardware support AI training workflows? In order to find the optimal weights, sparse matrix multiplications are distributed to tens of thousands of GPUs. The GPUs would go through a compute, exchange, and reduce cycle — the GPUs each compute intensively themselves, then synchronize with other GPUs to average and reduce their computations together, and then another cycle starts.
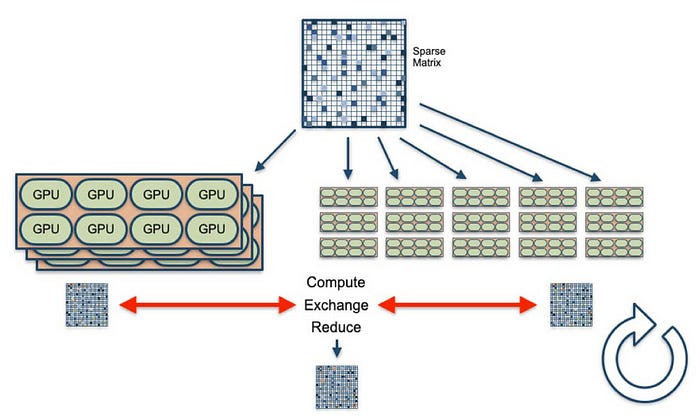
Ultimately, if we want to train the model as fast and as precisely as possible, we would need more GPUs and other servers. However, GPU utilization does not scale as we add more of them. The more GPUs are in use, the more GPU-to-GPU communication and synchronization there is. As data is being transmitted across more GPUs, GPU utilization starts to drop due to idle time amid data transmission, making it more expensive to train the models.
Computational Power: From the compute-exchange-reduce cycle shown above, we can see that there are intensive matrix multiplication operations for each iteration, which grow as the model gets larger and needs higher precision. Taking GPT-3 as an example, the 175B version requires 3e23 FLOP (Floating Point Operation) of computation for training. If we are using the most available state-of-the-art GPU, Nvidia A100, which can conduct around 312 TeraFLOP per second (TFLOPs), a single GPU needs 30 years to train GPT-3 without factoring in actual utilization.
Training Time: It took OpenAI 34 days to train GPT-3, and Meta 21 days to train LLaMa. As we have done the calculation above, thousands of GPUs (e.g., 2,048 A100 used to train LLaMa) are easily needed for training these LLMs in order to achieve a reasonable training time. Due to GPU shortage and communication loss for using too many GPUs, the largest LLM usually takes ~1 month to train for a good value for cost.
Memory Constraints: For all these LLMs, the weight tensor usually has a size of a few hundred GBs. The newest AMD MI300x (which has 2.4x memory of Nvidia’s H100) still can’t store the entire weight on a single chip, so larger on-chip memory would give the AI chip more flexibility when dividing the training workload and avoid communication. From the below graph, it is clear that on-chip memory size was growing at a slower pace compared to the model size (directly contributes to weight size). In the future, even though the model size might not grow as fast as the previous years, we might see more GPT-4-like multi-modal models, which could contain image, voice, or video capability, resulting in more complex memory requirements.

Finetuning:
Now that a base model is ready, finetuning is performed so that the model can achieve certain desired performance, or to be used for a particular task.During finetuning, new dataset that is specific to a task will be used. Unlike pre-training, here, the dataset is smaller in size and more specialized. The weights will continue to be updated here based on the new and more specific data used.
Finetuning an open-source model brings many benefits such as cost- and time-saving, while using well-performed models without having to train one from scratch. One can use as little as only one GPU for finetuning (vs. thousands of GPUs used in pre-training), and finetuning can be done in just one day. For example, the training of Vicuna-13B, finetuned on LLaMA, was only $300. Here, Databricks also laid out the instructions for finetuning Hugging Face models on a single GPU.
I’ve also seen closed-source model developers partnering with finetuning startups to help their customers better refine the base model. For example, Cohere partnered with Weights & Biases to experiment customized models for customers’ specific use cases. When training the first version of its Command model, Cohere leveraged the annotation workforces and high-quality datasets at Scale to make it happen.
However, I’d note that there are use cases where finetuning might not work so well, and that training from scratch might be needed. For example, finetuning the pre-trained models for completely irrelevant tasks, or finetuning from pre-trained models that are not very generic in the first place (i.e., finetuning BioGPT for legal use cases is probably not a good idea).
What are some ways of finetuning?
Repurposing a pre-trained text-generating LLM for a different type of application, such as sentiment analysis, could require changing the architecture of the LLM (e.g., freezing the attention layers of the transformer model while training the task-specific layer on top of the pre-trained model).
Unsupervised Finetuning uses unstructured dataset and updates the knowledge of LLM to a specific domain (e.g., medical, legal, etc.), essentially adjusting the model from source domain to the target domain.
Supervised Finetuning (SFT) uses high-quality question-answer pairs to finetune the model for human-preferred generation. The prompt-response paired data can either be curated by human manually or generated from other LLMs. In the case of ChatGPT, human-written, low quantity, and high quality pair data was used for it to follow user instructions to perform specific tasks. Instruction-tuning is a subset of SFT, guiding the LLMs to follow the chain-of-thought similar to human’s.
Reward Model (RM) Finetuning: similar to SFT, it also uses prompt-response pairs. Yet here, each batch of data consists of two prompt-response pairs — the same prompt but one with higher-score response and another with lower-score response. Here, the LLM learns to predict consistent with the preference, i.e., higher-score response.
Challenges and Requirements (compared to pre-training):
Computational Power: Usually the finetuning compute is as intensive as pre-training, because it is conducted on the same model. However, the amount of data and number of iterations required to run finetuning is way less. As a result, the total amount of compute power needed (FLOP) is in a more reasonable range for more companies to get involved.
Training Time: Since the total compute required is reduced by many order of magnitude, the total training time would usually fall into the range of hours to days, using less number of compute devices as well (GPU).
Memory Constraints: Due to the weight size being the same from pre-training to finetuning, the memory requirements are the same, needing multiple GPUs at least to be able to train.
RLHF:
Reinforcement Learning from Human Feedback (RLHF) is another way to optimize model performance. Models like ChatGPT and Claude are all LLMs that have gone through RLHF.
Think of RLHF as the interaction of a human agent with the environment. The first step in RLHF is to create a Reward Model (RM) by having human annotators rank and rate different model outputs, the reward signals. Those reward labels are then used to guide LLMs to adapt to human preferences, by aligning the behaviors of RM to the preferences of human annotators, thus giving it “human feedback.” These steps are then reiterated with the LLMs continuously “improving” from the reward signals. RLHF is particularly useful when evaluating behavior is easier than generating it.
To date, RLHF is largely a research territory. The result of RLHF depends on the quality of the inputs from human annotators. Additionally, bad behaviors could still happen even with RLHF. But with the emergence of open source LLMs, base models are becoming more “accessible.” It would be more cost-efficient for people to use state-of-the-art models. As such, I expect more developments around the applications of finetuning and RLHF, for people and companies to directly adapt models into specific use cases.

Deploy and model hosting:
Now that the LLMs are trained and fine-tuned, we will need to put LLMs into an environment for production (inference) and to be used by end users — the so-called model deployment and hosting process.
Here, people choose how and where to deploy the model, whether on premise or cloud. Factors that influence the decision include latency (e.g., the delay customers might experience to get a response from the chatbot), hosting costs (which depend on the computational power and memory required based on model size), and even safe deployment (to reduce harm and biases).
Usually, those fine-tuning startups will also handle the deployment process.Users go to all-in-one platforms like Cerebrium, either with base models of their choice, or to explore pre-built models on the platform. These platforms often create a serverless environment for the users, where they don’t need to worry about choosing the infrastructure. Users could finetune models on these platforms, and then once ready, they ship productions directly on the platform. Some even allow users to monitor their models post-deployment. Other “deployment-only” startups like BentoML take trained models and then help users schedule inference productions.
Model evaluation and monitoring:
Continuous evaluation and monitoring is needed throughout the model development process, so customers can learn how to further refine them, and what kinds of additional data are needed. There is also growing attention to more responsible model development and releases, which need to be monitored throughout the process. Model evaluation is also important, as there are many LLMs to choose from for customers to build products.
Below are some factors that people would consider when evaluating LLMs. Other key factors include explainability, reliability, limitation, and etc. For models that are used commercially, a very important metric is how well it aligns with customer needs and expectations, as what Jasper’s Director of AIdescribed — “form follows function.”
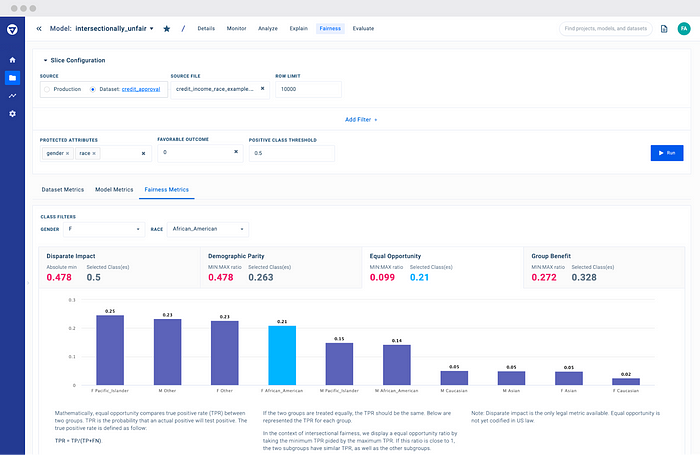
Safety / fairness: Biases are unavoidable for LLMs. Datasets are biased inherently. And biases may also come from human annotators when curating the dataset. All those biases could even be reinforced when the models pick them up. As such, we will try our best to avoid the unfairness. Startups like Fiddler detect biases in datasets and LLMs in real time. The figure below shows how Fiddler monitors metrics such as disparate impact, demographic parity, and equal opportunity in the dataset. While Arize AI helps customers trace biases, and compare fairness metrics among different model versions.
Accuracy measures how consistent the model outputs are with the expected results. Companies like Arthur AI proactively detects and reacts to model drifts. While TruEra helps evaluate how much of model drift can be explained by feature change. Below is a list of some commonly used evaluation metrics.
BLEU (Bilingual Evaluation Understudy) score is a metric commonly used to assess the quality of machine-generated translations vs. reference translations.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) score is often used to assess the quality of machine-generated text summaries vs. reference summaries, and used in text summarization tasks. It calculates the syntactic overlap between candidate and reference summaries.
BERTScore assesses the quality of text generated by capturing the semantic meaning, generated by the BERT model.
Robustness evaluates if the model can maintain model performance under adversarial attacks. Fiddler has an Auditor product that analyzes how models will respond to subtle variations in prompts, and compares outputs vs. expected outcomes. It also leverages LLMs to generate variations in prompts. I’ll talk more about adversarial attacks in the below “Security” section.
Model governance and security:
Models are actually very vulnerable. Open-source models might be more vulnerable as access to them is unconstrained, so it would be harder to control the misuse.
First of all, the data that the LLMs are trained on could possess unsafe or dangerous information. So the training process might augment the potential harm.
Additionally, models are subject to adversarial attacks such as prompt injection. By carefully or maliciously crafting the prompts, one can “lure” the models to give unintended responses and influence their behaviors. Researchers at Carnegie Mellon University actually successfully attacked ChatGPT. If you simply ask ChatGPT “how to build a bomb,” the machine knows it cannot give you the answer because there could be harmful impact. But if you ask it to write “step-by-step” guides on how to conduct certain criminal activities, it would actually give you the details… See example below. Quite scary.

Also, because models have limited short-term working memory (they are not database themselves), they are not able to cite where they have got the answers, i.e., they just don’t remember. As such, hallucination could happen, when the model generates answers that are not real, or that do not make any sense. In this case, the responses the models provide are probably not related to the training data, but based on the prompts themselves.
To mitigate such risks and avoid these attacks, one potential approach is to also expose the LLMs to unsafe or harmful content when training — adversarial training, such that the LLMs will learn to identify what is safe and what is not. We can then guide the models to generate safe responses even when they are given unwanted prompts. Another approach could be filtering the data input before the data is used in model development and production. Companies like Robust Intelligence would detect anomalies from both the inputs and outputs in real time, as well as screen the new datasets that would be exposed to the models.
The good thing is that the model-developers are working together to build a responsible future. Just last week, seven of the model-makers, both open-source and closed-source, both cloud service providers and startups, including Google and OpenAI, voluntarily committed to the safe, transparent, and secure development of AI technology, to the Biden-Harris Administration. Look forward to both building and using AI more securely.
Conclusion:
Here is a ChatGPT-generated conclusion:
“In conclusion, the emergence of Large Language Models (LLMs) has brought about a revolution in the field of artificial intelligence and natural language processing. These powerful models have demonstrated extraordinary abilities to comprehend and generate human-like text, revolutionizing various applications, from virtual assistants and chatbots to content creation and translation. As their impact on society grows, it becomes vital to address ethical considerations and potential risks to ensure their responsible use.
Delving deeper into their training process and exploring innovative applications will provide valuable insights into their potential and limitations. Let us embark on this exciting journey together, exploring the boundless possibilities of LLMs while being mindful of their implications. Together, we can ensure that LLMs become a force for good, transforming our world and enabling a brighter, more connected future.”
References:
https://karpathy.ai/stateofgpt.pdf
https://www.leewayhertz.com/fine-tuning-pre-trained-models/
https://research.aimultiple.com/llm-fine-tuning/
https://huggingface.co/blog/rlhf
https://bdtechtalks.com/2023/07/10/llm-fine-tuning/
https://arize.com/blog-course/large-language-model-llm-deployment/